
Closed-set
- 일반적으로 생각하는 classification problem 이다 = input 을 넣으면 정해진 N class 의 output으로 mapping 해준다.
- 학습한 후에는 학습하기전 정해놓은 class에 포함되지 않은 새로운 사람을 추가하거나 있는 사람을 없앨 수 없다.
-> 사람은 굉장히 많고 수시로 관찰하는 clalss가 추가/제외되므로 실제 Face Verification/Identification에 사용하기 어렵다.
-model은 학습하면서 주어진 class를 space안에서 구별할 수 있는 hyper plane을 찾게된다.
Open-set
-아예 처음보는 클래스에 대한 데이터도 처리해야 하므로 model은 모든 데이터에 대해 generalize해야한다.
-model은 학습하면서 metric-learning problem을 풀게된다.
*metric-learning problem = 일종의 similarity metric을 배우는것으로, 서로 구별되는 discriminative features를 뽑기위해 학습한다.
-hyperplane으로 image를 separate하기 보다는 input space를 재정렬 하게되는데. 비슷한 이미지는 가까이 붙이고 다른 이미지는 멀리 떨어뜨리는, 일종의 clustering problem을 풀게된다.
-그러므로 학습된 model은 data간의 distance matrix를 만드는데 사용 할 수 있고, metric learning이라고 불리는 이유가 된다. (distance metric 자체를 learning을 통해 학습하므로)
Contrastive Loss
-2005, Yann Le cunn이 처음 소개
-처음목적은 Dimensionality Reduction = inforamtion을 최대한 보존하면서 dimension을 줄이는 mapping 찾기.
-> unseen data에도 generalize 해야하고, 주변간의 관계도 유지하면서 dimension을 줄여야한다.
-> 같은사람이면 사진속 이미지에서 비슷할것이다+ 다른사람이면 이미지간 다를것이다.
->사진마다 찍히는 환경(포즈,조명,크기등)이 모두 다르므로 generalize 하기 위해선 point wise 비교하는것보다는 좀더 높은차원(=추상화가 더많이 된)의 feature 차원에서 비교하는것이 좋을것이다 (코가높다, 눈이크다 등등)
-> feature embedding 한 후에 둘간의 유사도를 비교(Siameses Network 내용 참조)해서 가까우면 같은 사람, 먼사람이면 다른사람이라 구분하자.
물론 같다 다르다의 기준은 threshold를 놓고 비교해서 결정하는데, 이것또한 학습한다.
->그럼 어떻게 학습하지?

위식은 class 가 같은경우 Y=0 이어야 Ls를 줄이는 방향으로, 다를경우, Y=1이어야 Ld를 줄이는 방식으로 작동되게 되어 있습니다. 일반적으로 같은경우 Y=1, 틀린경우 Y=0을 택할것 같은데 다르게 되어있네요...
1-Y, Y가 반대로 된것같은데.. 아시는분 있으면 댓글 달아주세요!
(1-Y,Y) 던 ,(Y,1-Y)던 컨셉은 달라지지 않으니 계속 설명하겠습니다.

처음에 나올때는 위 두번째 D 식처럼 Euclidean distance를 사용했지만, 다른종류의 similarity metric (Manhattan distance, Cosine similarity,etc.)도 사용가능하고 실제로 요즘은 hyper sphere 위에 mapping 한다는 개념으로 cosine simlarity를 사용하여 Theta+margin 개념을 사용하고 있다.
첫번째 L식으로 보게되면 Cross-Entropy(이하 CE)와 굉장히 유사하게 생겼는데 CE는 Classification task를 수행하면서 network에서 결과로 나오는 probabilty값을 사용한다면 , Contrastive loss의 Ls(similar class)와 Ld(dissimilar class)는 metric learning loss로써 network에서 결과로 나오는 포인트의 위치관계를 담고있다.
-> 이것이 cross-entropy를 metric learning 으로 사용하지 않는 이유인데, 즉 , CE는 이미지에서 뽑은 feature가 비교하고자 하는 이미지에서 가까운지,먼지 상관없이 뽑는법을 배우게된다.
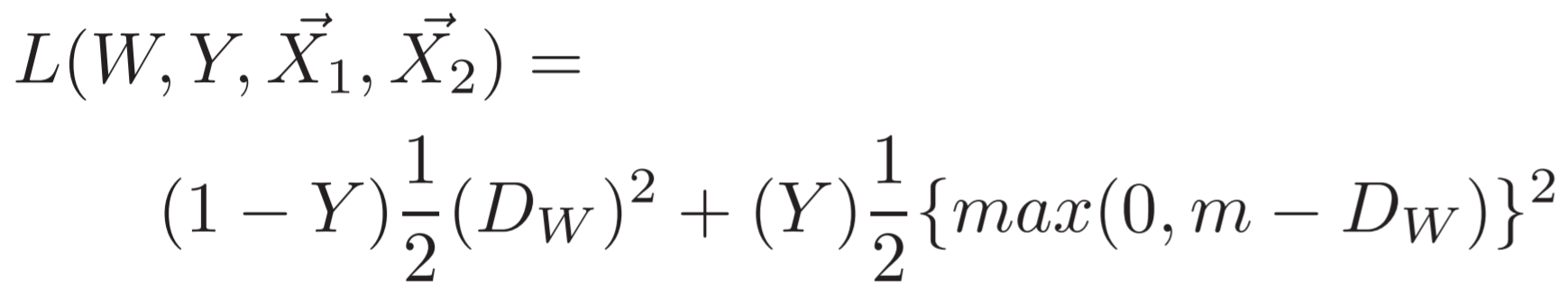
Ls,Ld의 해당하는 부분의 식을 그래프로 그려보면 바로 학습을 진행할경우 같은 class는 0에 가깝게, 다른 class는 m(margin)보다 크게 보내는 Loss function임을 알 수 있다. 다만 Le cunn이 Ld에 1/D같은식을 안쓴이유를
Equalibrium이라는 intuition을 얘기 하는데, 이는 GAN에서 얘기하는것과 비슷하다.
Loss를 무작정 극단으로 치우치게 해서 학습(class가 다른 것들을 무한이 멀리보냄)하게 되면, 이미지상 비슷하지만 다른class 또한 무한히 멀리 보내게되고 그 반대도 학습한다. 결국 학습을 끝냈을때(Equilibrium에 도달하기 힘들어 학습하는데 오래걸리기도 함) generalization 능력을 잃게된다.
아래는 블로그 원작자의 원문 설명은 다음과 같다.
- If we were to use the same “margin” concept for similar points, we won’t force the similar points to be as close to each other as possible — thus a lot of them would be located near the margin and could be easily pushed out of it, which would make the training unstable and difficult to converge.
- If we were to use the {1 / Dw} term for the dissimilar points, then we would continue pushing away white dots for eternity (in theory) or for just a very long time, even when the results are already separable and usable for a nearest-neighbour classification. This would also make it difficult to reach the Equilibrium point, is simply unnecessary and may push dissimilar points TOO far away, which may worsen the generalization performance of the model.
모델의 개략적인 모습은 다음 사진과 같다.

아래는 MNIST의 Contrastive Loss를 적용시켰을때 feature map의 모습
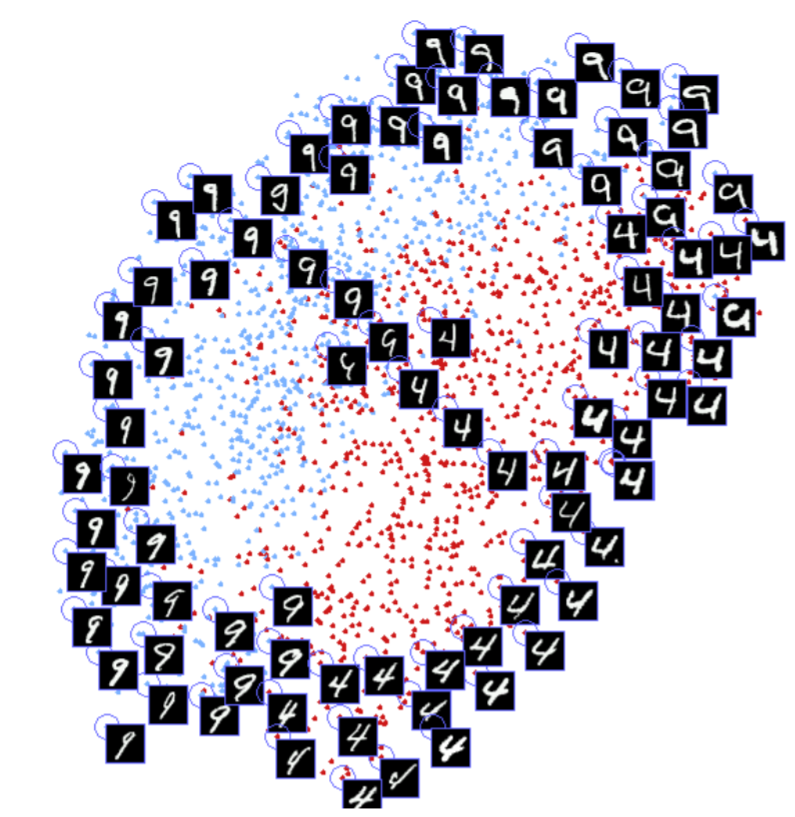
출처 : medium.com/@maksym.bekuzarov/losses-explained-contrastive-loss-f8f57fe32246
사진, 식 출처 : arxiv.org/abs/1704.08063
Losses explained: Contrastive Loss
This is a series of posts explaining different loss functions used for the task of Face Recognition/Face Verification.
medium.com
+나의 생각
'인공지능 > Face Recognition' 카테고리의 다른 글
| [Paper Review] MV-Softmax (SV-Softmax, SV-X-Softmax) 정리 (0) | 2021.02.09 |
|---|---|
| Face Recognition 트렌드 정리 (0) | 2021.01.29 |
| [Paper Review] L2Softmax, NormFace 총 정리 (5) | 2021.01.27 |
| [Paper Review] Center loss 정리 (4) | 2021.01.27 |
| Triplet Loss, Triplet Mining 정리 (5) | 2021.01.27 |