1. 개요
Jane Street Market이라는 주가예측 회사에서 연 competition
실제 시장 결과를 토대로 얻어진 여러 feature들로 represent 되어있는 data를 보고 1(accept)/0(reject)할건지를 결정해서 maximum return을 하는 own quantitative trading model을 만들어라.
단, 사용하는 data들은 익명화 되어있음.
2.DATA
총 네개의 file
1. train.csv
:학습에 사용하게될 데이터.
-shape= (2390491, 138)
-2390491 = 총 500일의 trading data, but 날마다 여러번의 trading 기회 -> 총 2390491번의 거래
-138 = date(날짜) + feature_{0....129}(익명화된 feature. ex.PER) + ts_id(index 1,2,3....) + weight(얼마나 넣을지) + resp_{1,2,3,4,0}(time horizen 짧게 투자할건지, 길게투자할건지 길게하면 risky하게 가능)
2. example_test.csv
: 가상 test set , time-series API가 알아서 test/prediction 할때 사용
3. example_sample_submission.csv
: sample submission, format 참조용
4. features.csv
-feature들의 metadata가 정리되어있음
(*metadata = data를 활용하기위한 data의 data)
-(30,130)
-30개의 tag들로 feature 130가지를 boolean으로 평가하는것 같은데 각tag마다 무슨 의미인지는 잘 모르겠음.
(*csv=comma separated value)
3.EDA Notebook으로 data 최대한 파악해보기
노트북 출처 : www.kaggle.com/carlmcbrideellis/jane-street-eda-of-day-0-and-feature-importance
train.csv
파일은 5.77G로 큼 불러들어 읽는데 시간이 좀 걸림
resp
: 뭐의 줄임말 인지는 잘 모르겠음. 다만 resp * weight=return 이라는것을 보면 가격 변동률로 예상됨.

maximum llikelihood estimation으로 time horizon T1,T2,T3,T4에 관계를 도출한 "Jane Street: time horizons and volatilities" written by pcarta 에 따르면. Time horizon 간의 관계는 다음과 같다.

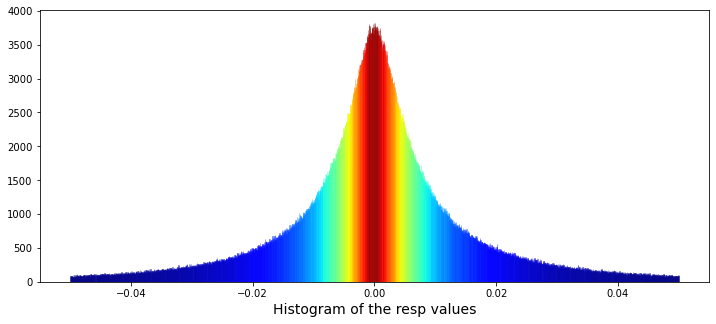
max(resp)= 0.44846
min(resp)=-0.54938
skew(3rd standardized moment) : 0.10
kurtosis(4th) : 17.36

Weight
: 얼마나 투자할지에 대한 수치로 추정 -> -값은 존재하지 않고 0값은 return에는 영향을 주진 않지만 dataset의 completeness를 위해 첨가했다고 대회측에서 작성.
min=0.00,
max=167.29, on dat 446
17% of dataset, weight=0

0.17와 0.34 두곳에서 peak 가 있는것으로 보아 two distribution의 중첩이 아닐까란 추론
two distribution=? (selling, buying)?


mean = -1.32 for small , 0.4 for large -> don't forget it is value of logarithm
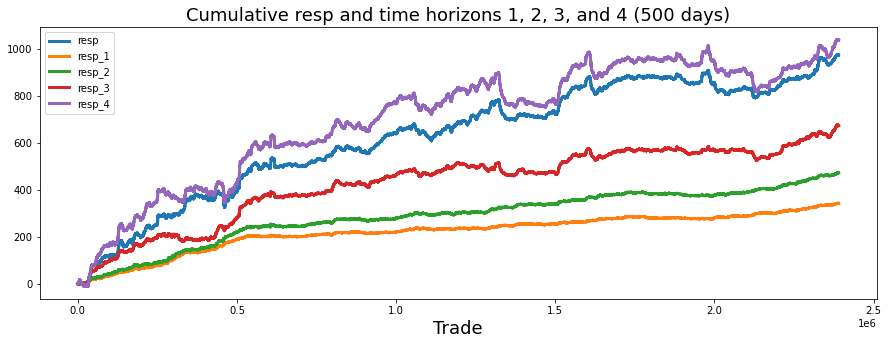
Cumulative return
: cumulative of return(weight * resp)

cumulative resp 은 우상향( 시간지나면 변동률 합산했을때 +) 였으나, weight을 곱하고 나니 하향을 띔(1아래로 떨어짐)
->이게좀 의문, 왜 모델 수익률이 -인지 ...
특히 resp 1,2,3 같은경우 time horizon이 짧고, 변동폭이 작음(conservative한 strategy 사용), lowest return

Time

85th day 부터 시장에 변화가 생겼거나, model의 변화가 생긴것으로 의견이 모아진다.

하루 6.5시간이 trading hour이므로 23400 sec을 각 하루 거래량으로나누어주면 위의 표가 나온다.
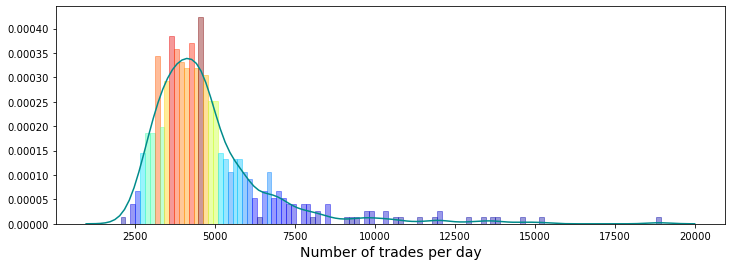
하루거래량(volatility)을 x축으로 놓고 해당하는 날짜의 수의 비율을 y축으로 표기
거래량이 많은날 = 일명 'volatile days'라 한다.

volatile days를 출력해보았을때 500일중 대부분 85일 이전에 위치한다
The Features
feature 0
: 1과 -1로만 이루어져있다.
1 : 1207005 번
-1 : 1183486 번
-true tag가 없다.

다른 feature와 달리 1이냐 -1이냐 에 따라 매우 다른 dynamic을 가진다. bid/ask, long/short, call/put, 혹은 가격변동에 따른 buy/sell order(=면 1, -면 -1)
나머지 feature들은 4가지로 분류(Linear, Noisy, Hybryd, Negative)
feqture 41,42, 43(Tag14)
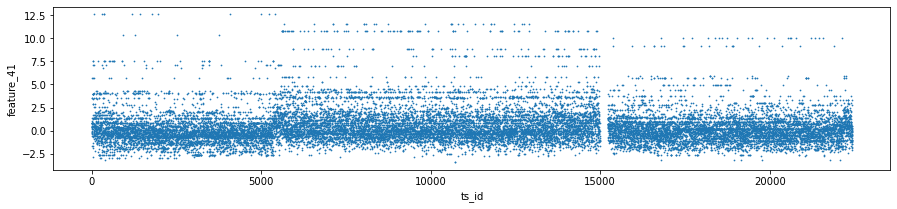


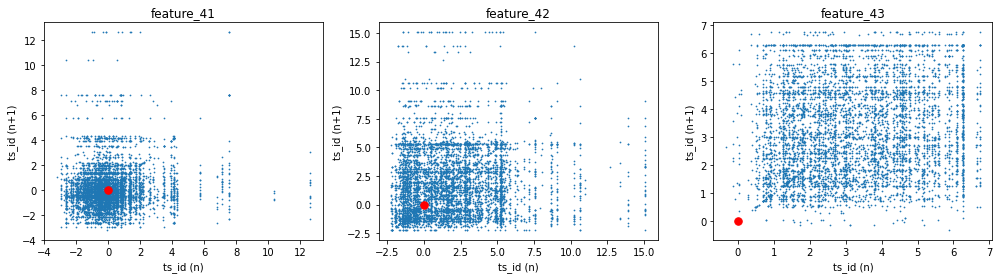
- 층이 discrete하게 나옴 -> security레벨같은 레벨개념의 feature일 가능성
- ts_id(n)과 ts_id(n+1)이 비슷한 값을 가지는 경향이있음.
feature 60,61,62,63,65,66,67,68
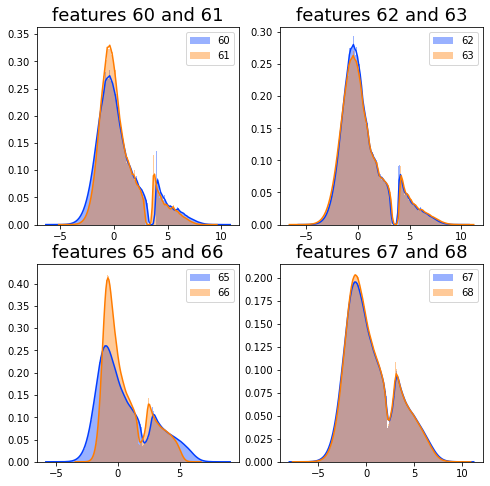
비슷한 경향이 있음

특이하게 feature_64는 0.7~1.38사이 big gap이 있음.
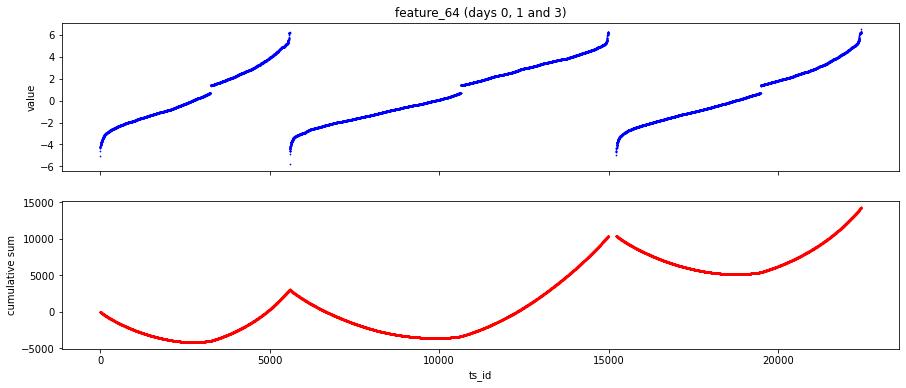
날별로 plot하면 위와 같고 날마다 반복되는 값의 maximum, minimum이 일정한걸로 보아 시간과 관련된 feature로 보임(장시간에 따른 tick 횟수라던가,,, 장 시작시간, 마감시간에 거래량이 늘어나므로) -> 가운데 빈곳은 break time이라는 해석이 있음.
feature_51 = log of the average daily volume of the stock
'Negative' features
: Features 73, 75,76,77(noisy), 79, 81(noisy), 82. Tag 23 section에 다포함
'Hybrid' features(Tag 21)
:noisy로 시작하지만 특정시점부터 linear 55,56,57,58,49 . Tag 21에 포함.
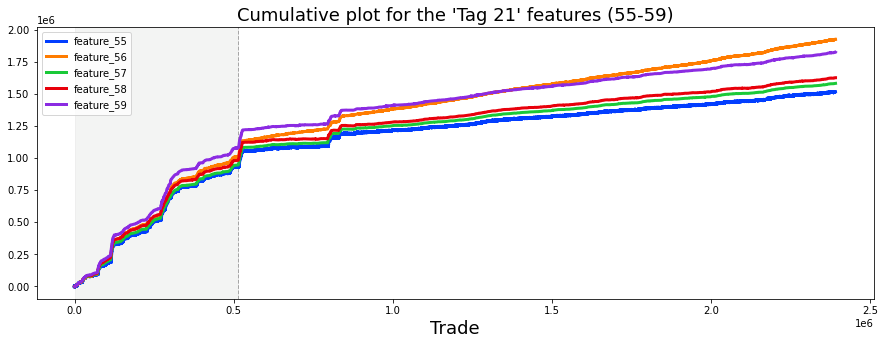
resp, resp_1,2,3,4와 대응 되는것처럼 보임 ->
- feature_55 is related to resp_1
- feature_56 is related to resp_4
- feature_57 is related to resp_2
- feature_58 is related to resp_3
- feature_59 is related to resp
If that is the case then
- Tag 0 represents resp_4 features
- Tag 1 represents resp features
- Tag 2 represents resp_3 features
- Tag 3 represents resp_2 features
- Tag 4 represents resp_1 features
i.e.
- resp_1 related features: 7, 8, 17, 18, 27, 28, 55, 72, 78, 84, 90, 96, 102, 108, 114, 120, and 121 (Note: 79.6% of all of the missing data is found within this set of features).
- resp_2 related features: 11, 12, 21, 22, 31, 32, 57, 74, 80, 86, 92, 98, 104, 110, 116, 124, and 125 (Note: 15.2% of all of the missing data is found within this set of features).
- resp_3 related features: 13, 14, 23, 24, 33, 34, 58, 75, 81, 87, 93, 99, 105, 111, 117, 126, and 127
- resp_4 related features: 9, 10, 19, 20, 29, 30, 56, 73, 79, 85, 91, 97, 103, 109, 115, 122, and 123
- resp related features: 15, 16, 25, 26, 35, 36, 59, 76, 82, 88, 94, 100, 106, 112, 118, 128, and 129
17개의 feature들을 각 resp(추측)에 맞게 plot하면 17*5=85 feature는 다음과 같이 떨어진다.
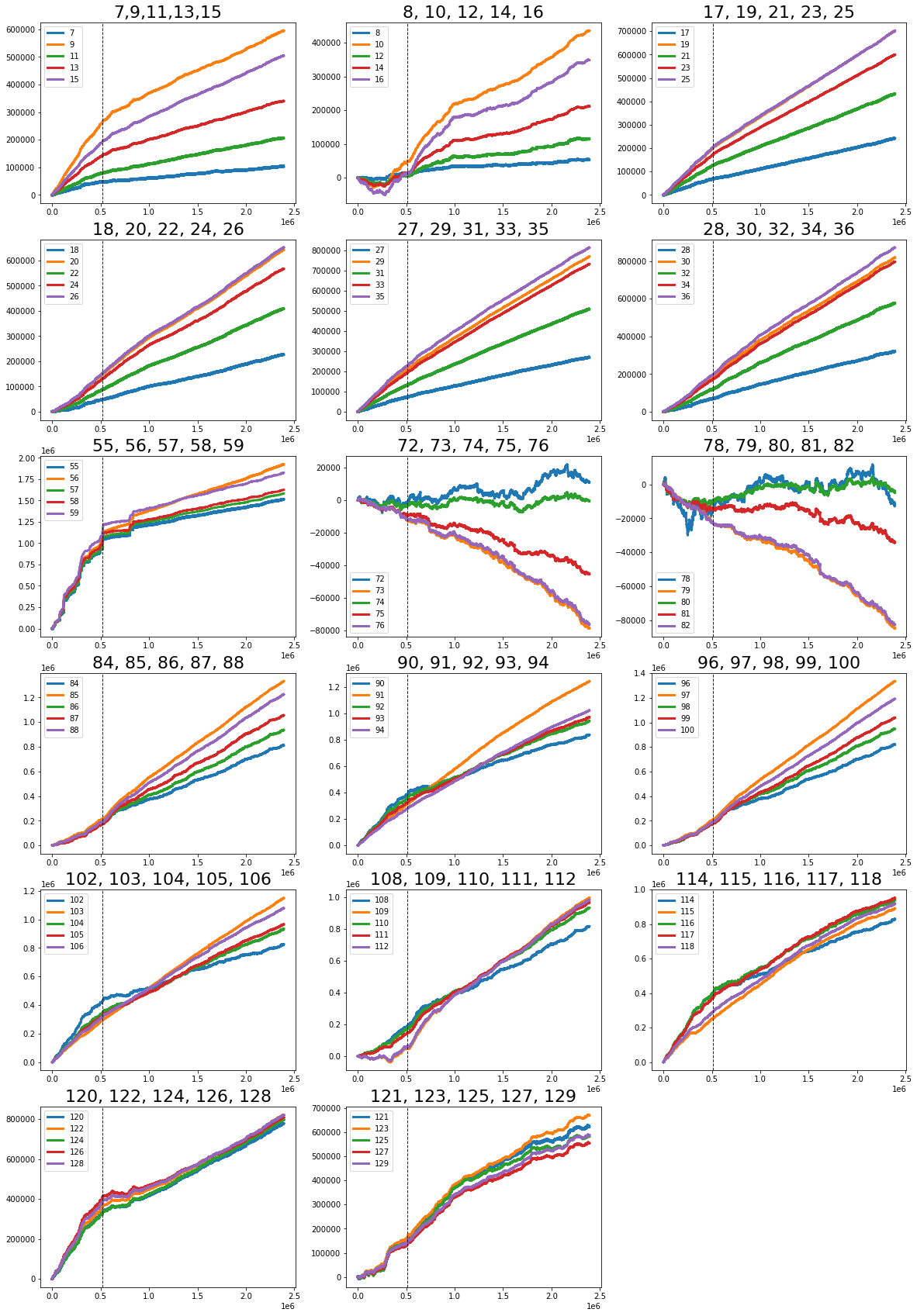
feature와 Tag관계


위와 같이 반복되는 패턴은 resp , resp1,resp2,resp3,resp4 의 관계로 보임. 순서는 Tag0부터 (4,0,3,2,1)

tag 는 적어도 1개에서 4개까지 가지고 있다. 예외로 feature_0는 0개의 tag
'Region'featuresTagsmissing values?observations
| Region | features | Tags | mnissing values? | observations |
| 0 | feature_0 | none | none | -1 or +1 |
| 1 | 1...6 | Tag 6 | ||
| 2 | 7-36 | Tag 6 | ||
| 2a | 7..16 | + 11 | 7, 8 and 11, 12 | |
| 2b | 17...26 | + 12 | 17, 18 and 21, 22 | |
| 2c | 27...36 | + 13 | 27, 28 and 31, 32 | |
| 3 | 37...72 | various | ||
| 3a | 55...59 | Tag 21 | All hybrid | |
| 3b | 60...68 | Tag 22 | Clock + time features? | |
| 4 | 72-119 | Tag 23 | ||
| 4a | 72...77 | + 15 & 27 | 72 and 74 | |
| 4b | 78...83 | + 17 & 27 | 78 and 80 | |
| 4c | 84...89 | + 15 & 25 | 84 and 86 | |
| 4d | 90...95 | + 17 & 25 | 90 and 92 | |
| 4e | 96...101 | + 15 & 24 | 96 and 98 | |
| 4f | 102...107 | + 17 & 24 | 102 and 104 | |
| 4g | 108...113 | + 15 & 26 | 108 and 110 | |
| 4h | 114...119 | + 17 & 26 | 114 and 116 | |
| 5 | 120...129 | Tag 28 | ||
| 5a | 120 | + 4 | missing data | |
| 5b | 121 | + 4 & 16 | missing data | |
| 5c | 122 | + 0 | ||
| 5d | 123 | + 0 & 16 | ||
| 5e | 124 | + 3 | ||
| 5f | 125 | + 3 & 16 | ||
| 5g | 126 | + 2 | ||
| 5h | 127 | + 2 & 16 | ||
| 5i | 128 | + 1 | ||
| 5j | 129 | + 1 & 16 |
Action
:trade/pass(1/0)
가장 간단하게 가격변동률(resp)가 음수일때 pass, 양수일때 trade 하도록 짜보면


day 294를 제외하고 고르게 나쁘지 않게 거래함.
missing values(=NAN)

빠진값의 pattern이 보인다. y축과 나란하게 빠진거 보면 일정 시간에 값을 missing 되었다 생각 할 수있다.
day 2 와 day294 는 missing value 가 없는데 이는 ts_id 자체가 매우 적고 feature가 빠지는 시간대에 안걸쳐 있었다 생각할 수 있다. -> outlier로 생각하고 빼도 될거같음
'인공지능 > 캐글' 카테고리의 다른 글
| [Jane Street] Overfitting 막기위한 기법들 (0) | 2021.02.14 |
|---|