시작하기 앞서
[Paper Review] MV-Softmax (SV-Softmax, SV-X-Softmax) 정리
개요 2019년 작성, 2020AAAI 발표한 논문으로 Face Recognition 성능향상 논문 트렌드중 Margin based Softmax loss (Arc, Sphere, AM, etc.) 과 Mining based Softmax loss(Focal loss, OHEM etc.) 를 한 Loss에..
mic97.tistory.com
본 게시물은 위 MV-Softmax 게시글을 읽고 Margin, Mining softmax loss 에 대한 이해가 된 상태라 가정하고 설명 하겠습니다. 안 읽으신 분들은 위 글부터 읽고 오시길 바랍니다.
개요
2020년 작성, 2020CVPR 발표논문으로 Face Recognition 성능향상 논문 트렌드 중
Margin based Softmax loss + Mining based Softmax loss + Learning Strategy를 한 Loss 에 합친 형태.
동기
'Margin based method는 학습과정 중 모든 Negative class에 대해 같은 wieght를 적용시킴으로써 각 sample의 어려움에서 오는 정보를 활용하지 못하고 있고,
Mining based method는 hard sample을 early training stage에서 너무 많이 강조함으로써 모델이 converge하는것을 방해하고 있다.
따라서 학습 과정에 따라 manually tunning이 필요 없는 adaptive weight을 결정하는 Loss를 만들어 Adaptive curriculum learning 을 구현하겠다.' 라는게 저자의 생각
알고리즘

MV Softmax를 충분히 이해하고 왔으면 위 알고리즘 을 보고 MV논문과의 다른점은 else절에 Negative cosine similarity에 곱해진 값이 변경된것 말고는 다른게 없다는 것을 알것이다. 자세한 차이점은 아래식을 보면 알 수 있다.
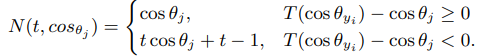

실제로 위 식을 제외하곤 나머지는 매우 유사하다.
Training data set을 학습 과정중 기준두개(1.True or Negative Class vector, 2.Negative중 hard sample 인지)
를 이용하여 총 세가지로 분류한 후, 각자 다른 loss로 최종 softmax 형태로 합쳐진다.
세가지 데이터는 아래와 같다.
1)True Class -> Margin softmax사용 cos(theta+M)
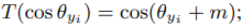
2) Negative Class 이면서 Hard -> t가 들어간 식 사용

3) Negative Class 이면서 Not hard -> 기존 cos (theta)

위 세가지 데이터 분류에대한 각 loss들이 아래식에 합쳐진다.

그렇다면 MV-Softmax(MV)와 달라진 t는 어떻게 Curriculum Learning(CL)을 구현 할까?
우선 MV, CL 둘다 식에 t가 들어가지만, MV의 t는 1.2처럼 고정된 값이다. 반대로, CL의 t는 sample의 어려운정도(cos(theta))와 Learning stage의 영향을 받는 변하는 값이다. 자세한 건 아래 단락을 보자.
Curriculum Learning 을 구현 하는 t
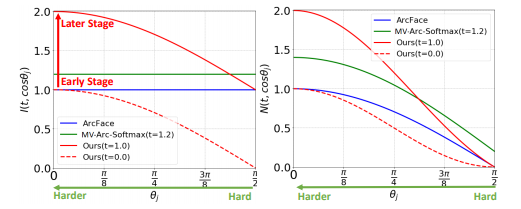
위 사진을 보면 Arc Face는 Negative class에 대해 가중치를 두지 않기때문에 1로 고정되어 있고,
MV-Arc-Softmax는 가중치를 두기대문에 t의 값이 1.2로 고정되어 있는 반면,
CL(위 사진에서 Ours)는 t값이 Learning stage, Hardness(theta)값에 따라 달라지는것을 볼 수 있다.
위 figure에서 plot되고 있는 정확한 식은 다음과 같다.
1)CL


2)MV-Arc-Softmax

3.ArcFace

다시 CL의 t로 돌아와서,
k번째 t는 위 식과 같이 결정되는데, 저자가 설명하길 위 식을 쓴 이유는
실험적으로 positive cosine similarity들의 평균값이 t로 사용되기 좋다는것을 알았지만, mini-batch마다 average 하는것은 너무 noisy 하고 unstable 하므로 Exponetial Moving Average(EMA)를 사용하였 다고 한다.
따라서 위 식에서 alpha는 momentum으로 0.99로 설정하고, t(0)=0, r=average of cosine similarity 를 의미한다.
처음에 t(0)는 0에서 시작하여 r값을 따라 가게 되는데 r값을 파혜쳐보면,
학습 초반엔 잘 못맞출 것이므로 theta~=phi/2(잘 못 맞춤) 일 것이고 cos(theta)~=0이므로 0에 가까울 것이다.
하지만 학습이 계속 진행되면 theta~=0(잘 맞춤) 일 것이고, cos(theta)~=1 일 것이므로 학습이 진행될 수록 1에 가까워 질 것이다.
즉 t는 학습 초기 0에서 학습이 진행 될 수록 1에 가까워지며, t 값이 커질 수록 Hard sample의 loss의 가중치가 커지면서 자연적으로 Hard Sample을 강조하게 된다.
실제 학습이 진행될때 t의 값의 변화는 다음과 같다.
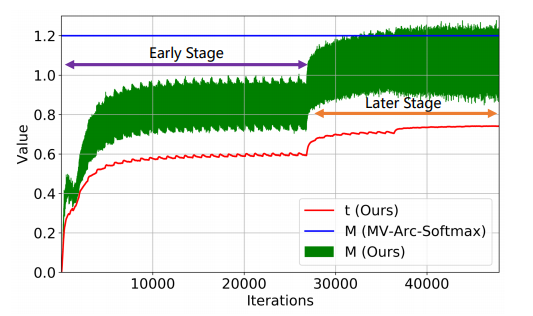
위 figure에서 M은 학습의 가능성을 보기위해 Loss를 미분한 식의 일부를 나타내고 식은 다음과 같다.

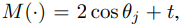
초록색이 위아래로 흔들리는것은 iteration 뿐만 아니라 samlple의 hardness(theta)값에 따라서도 변동이 있다는것을 보여준다.
Decision Boundary 비교

True Loss = Negative Loss를 했을때의 theta 조건 -> Decision Boundary
보라색 선이 early stage에서는 softmax(파란선) 보다 쉽게, Later Stage에 갈수록 Arc Face(분홍선)보다 어렵게 가고 있는것을 볼 수 있다. 즉 학습단계에 따라 Margin이 어려워지는 효과를 보여준다.
Ablation study
1. fixed t vs Adaptive t
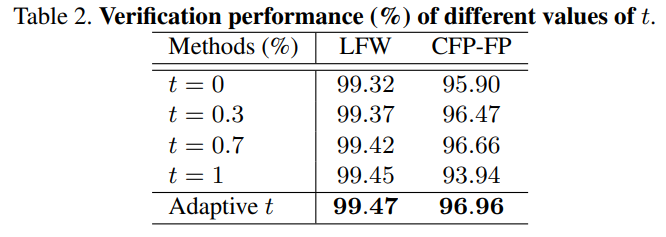
t의 값을 fixed 시킨것보다 Adaptive 하게 결정되는 본 논문의 t가 verification performance가 더좋다.
2. t 설정하는 Statistic 에 따른 영향
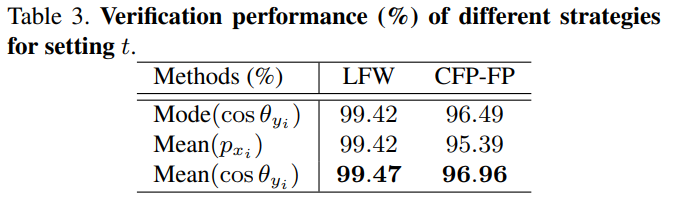
본 논문은 t를 r=mean of positive cos(theta)의 EMA로 나타냈는데, 다른걸 쓰면 어떨가에 대한 고찰로
mode는 most frequent value를 의미하고
p는 본논문 loss 식에서 log 안에 들어가는 값으로 다음 식과 같다. p 또한 0,1사이의 값이다

3. Training Convergence

본 논문은 Large margin을 할수록 convergence를 보장하기 힘들다고 주장한다. (의미적으로 당연 한게 모든 sample들에 margin을 줘야하는데 margin이 클수록 학습이 힘들거나 margin을 가지면서 구별하는게 불가능 할 수 있다.) 특히 큰 margin이면서 MobileFaceNet같은작은 backbone Network 에서 Diverge할 가능성이 크다고 한다. 위 figure에서 보이듯이
1. m을 높이면 converge가 힘들어짐
2. 자신들의 모델이 convergence에 이점이 있음 이는 CL의 이점을 살린 것으로 생각됨.
3. 성능이 같은 조건일때 기존 보다 좋음
을 주장 하고 있다.
출처
Yuge Huang, Yuhan Wang, Ying Tai. Curricular Face : Adaptive Curriculum Learning Loss for Deep Face Recognition, 2020 CVPR
'인공지능 > Face Recognition' 카테고리의 다른 글
| [Paper Review] AdaCos 정리. (0) | 2021.05.13 |
|---|---|
| Arc Face Easy Margin에 대해 (0) | 2021.03.09 |
| [Paper Review] MV-Softmax (SV-Softmax, SV-X-Softmax) 정리 (0) | 2021.02.09 |
| Face Recognition 트렌드 정리 (0) | 2021.01.29 |
| [Paper Review] L2Softmax, NormFace 총 정리 (5) | 2021.01.27 |