개요
2019년 작성, 2020AAAI 발표한 논문으로 Face Recognition 성능향상 논문 트렌드중
Margin based Softmax loss (Arc, Sphere, AM, etc.) 과
Mining based Softmax loss(Focal loss, OHEM etc.)
를 한 Loss에 합친 형태를 가지는 최초의 논문이다. (논문 주장).
SV-X-Softmax와 MV-Softmax의 차이
읽어 보았을때, SV-Softmax(2018) 논문은 MV-Softmax(2019)논문의 arxiv preprint 버전으로 다른점은 다음 네가지정도 로 보이고 intuition과 사용된 equation 은 같으므로 다음 단락부터는 SV-Softmax에 대해서만 설명하겠다. (정확히는 SV-Softmax 논문중 margin 을 첨가한 SV-X-Softmax 와 MV-Softmax의 차이.)
1. h(indicator function)에 fixed 버전을 넣은 실험진행.
SV-Softmax : h에 adaptive version (cos(theta)가 다른 정도에 따라 weight 조정)이 기본.
MV-Softmax : h의 adaptive version + h fixed version( hard sample 로 분류되면 얼마나 어려운지 ( cos(theta)값이 얼마인지 상관없이) 같은 weight 적용)과 비교하는 실험 추가.
2. Training data set의 차이.
MS1M-vlc : Trillion-pairs consortium(deepglint2018)에서 MS1M의 noisy 한 데이터를 cleaning한 버전.
(3,923,399 imgs /86,876 ids)
MS1M-vlc-R : MS1M-vlc 에서 Test data set(LFW,CALFW,CPLFW,AgeDB,CFP,RFW, MegaFace)와 overlap되는 id 제거버전, 겹치는 id list는 github 에 제공.
(3,280,000 imgs/ 72690)
(github.com/xiaoboCASIA/SV-X-Softmax/blob/master/deepglint_unoverlap_list.txt)
MS1M -> MS1M-vlc -> MS1M-vlc-R
(SV-Softmax) (MV-Softmax)
3. Test data set의 차이
SV-Softmax : Mega Face ,Trillion Pairs(gallery = subset of Flickr photos, Probe set= Facescrub)
MV-Softmax : Verification(LFW, CALFW, CPLFW, CFP, RFW), Identification(MegaFace, Trillion-Pairs)
4.Indicator function 내 t 범위 차이.


위부터 각각 t=1,t=0일때 기존 softmax.
Motivation
Face Recognition 분야 는 크게 두가지 mining based(Focal loss, OHEM etc.)와 margin based(Arc, Sphere, AM, etc.)로 발전하였는데 각자의 단점이 있다.
Mining based loss는
1. hard example의 정의가 애매.
2. loss나 model complexity로 hardness를 empirically 측정해야한다.
Margin based loss 는
1.GT class vector 와 비교에서만 discriminatve feature를 배운다(self-motivation=GT class). 다른 class vector와의 비교(other-motivation=Non-GT class = Negative Cosine Similarity)로 얻는 discriminative power를 얻을 수 없다.
2. class마다 fixed된 weight을 사용한다.(MV-Softmax추가)
-> 두 가지 방법의 장점을 하나로 integrate 하는 loss function 제안 ->MV-Sofmax
MV-Softmax-Loss
~아이디어의 flow대로 식을 정렬하자면.
1.Softmax Loss

2. Mining based Softmax Loss

Py, probability는 softmax layer를 지난 output을 의미하며, g function을 통해서 sample mining효과 구현.
ex1) OHEM : g(Py)=0 for easy sample, g(Py)=1 for hard sample.
ex2)Focal loss: g(Py)=(1-Py)^gamma

3. Margin based Softmax Loss

~f function을 통해 margin을 구현.
ex)




4.Naive Mining-Margin Softmax Loss

~Naive하게 Mining과 margin을 합친버젼. 이렇게 구현할시 Margin based와 Mining based의 각각의 단점이 여전히 남아있다.
단점
1. GT와의 마진만 고려(Non-GT고려 x)
2. Hard sample 정의에 대한 애매함.
5. SV-SoftMax Loss

where,


~Binary mask function, I() 와 Indicator function, h()를 Softmax에 추가함으로써 Naive Mining-Margin Softmax loss의 단점 해결.
Intuition
1.Binary mask function, I에 대한 고찰.

cos(wy,x)=정답 클래스와의 각도.
cos(wk,x)=정답이 아닌 클래스와의 각도. ( when k!=y).
즉, cos은 phi 까지 감소함수 이므로,
cos(wy,x)>cos(wk,x)인 상황
= 샘플과 정답간의 각도가 샘플과 오답간의 각도보다 작은 상황
= 샘플이 오답보다 정답에 가까운상황
-> 잘 분류하고 있으므로 loss에 weight 높이지 않음 -> 기존 cos 사용.
반대로,
cos(wy,x)<cos(wk,x)인 상황
= 샘플과 정답간의 각도가 샘플과 오답간의 각도보다 큰 상황
= 샘플이 정답보다 오답에 가까운상황
-> 잘못 분류하고있으므로 어려운 sample이라 인지, loss에 weight 높임 -> 기존cos에 h 곱함.
2.Mining based Loss (Focal Loss) 와 SV-Softmax의 차이점

~기존 Mining based loss와 SV Softmax 둘다 loss를 고쳐서 위 식의 관계를 만들어 Easy sample 대비 Hard sample의 loss를 늘리려 한건 같으나. 위 관계를 구현하기 위해 취한 방법이 다르다. 아래 사진을 보자

~SV-Softmax(왼쪽)은 전체 Loss식(Cross Entropy, 위 figure에서는 -log(Py) 에서 probability 값을 조정함으로써 loss를 높였고, Focal Loss-Softmax(오른쪽)은 probability는 그대로 두고 Loss식 자체를 바꿈으로써 Hard sample의 loss 비중을 높였다.
3. Margin Based Loss 와 SV-Softmax의 차이점


~위 식을 보면서 명심해야할것은 theta 1은 ground truth class 이고, thetat 2는 non ground truth class이다.
또한, 기존 Margin based Softmax 의 f, margin function은 theta1에 대한 함수이고(self-motivated), SV-Softmax식에서 h, indator function은 theta2에 대한 함수이다. 등호가 어디 있는지는 그렇게 중요하지 않지만, 집중하는 weight vector에 따라 서술한것으로 추정된다(GT,Non-GT).
다 정리해서 한문장으로 설명하면 Margin based Softmax는 정답에 가깝게 학습, SV-Softmax는 오답에 멀게끔 학습 으로 이해하면 편하다.(실제로 최종 loss를 보고 loss를 줄이는 방법으로 파라미터를 따라가다보면 그렇다. 이에 대한 설명은 4번 단락에서 그림과 함께 설명하겠다.)
4.총모델에서 직관이 사용되는 위치 (+ Margin only,Mining only와의 비교)

~SV softmax는 위 그림에서 빨간 박스에 해당하는데, 해당위치에서 loss를 바꿈으로써 원래 Margin-based(파랑), Mining-based(보라)가 하는 역할을 one framework로 합쳤다.
구체적으로 파랑과의 비교를 보면, 우선 많은 cos(theta)중 바뀌는 부분에 차이가있는데, 파랑은 GT class의 값을 바꾸고 빨강은(Non-GT class의 값을 바꾼다). 이때 모든 Non-GT class의 값을 바꾸지 않는것은, Loss 식에서 Binary mask에 의해, 모델이 정답이 아닌 클래스 더라도 Support Vector(Hard Sample)로 분류될만큼 오답에 가깝게 분류하지 않았기 ㄸ매문이다.(k!=y 이나, I=0인경우. 즉, cos(wy,x)>cos(wk,x)인 상황)
보라와의 비교를 보면, 빨강은 Loss 식 안의 probability라고 명시되는 Logit의 Softmax를 거친후의 output을 바꾸는 반면, 보라는 마지막단에서 계산되는 Loss 자체를 바꾼다.
5.SV-X-Softmax(MV-Softmax)
지금까지 위에서 설명한 SV-Softmax에 margin function, f를 추가한 Loss.
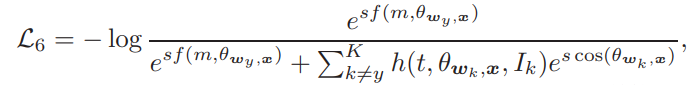

즉, 원래 SV-Softmax에서 오답에 집중(loss 식에서 sigma 부분) 함으로써 Mining based와 Margin based를 구현했다면,마진, f function을 추가함으로써 정답에 가까워 지게끔 하는 효과 구현.
i.e. 정답 class에는 가깝게 오답 class에는 멀게끔을 한 loss 에 구현.
이 loss가 MV-Softmax논문의 loss로 사용된다.
6.Optimization
SGD를 위해서 직접 partial derivative를 구해봤는데, 기존 softmax에서 x-term(weight에 대한 미분시), w-term(x에대한 미분시)가 생기는것을 제외하고는 똑같다. -> 학습 가능하다.

최종 알고리즘

본 Loss는 CNN 통해 나오는 feature map을 다시 head(softmax부분)를 거쳐서 학습하므로.
위 알고리즘 식에서 Theta는 CNN 안에 weight를 의미하고
W는 head부분의 weight을 의미한다.
논문 출처:
1. Xiabo Wang et al. Mis-classified Vector Guided Softmax Loss for Face Recognition(MV-Softmax), 2020 AAAI
2. Xiabo Wang et al. Support Vector Guided Softmax Loss for Face Recognition(SV-Softmax), 2018, arxiv preprint
Support Vector Guided Softmax Loss for Face Recognition
Face recognition has witnessed significant progresses due to the advances of deep convolutional neural networks (CNNs), the central challenge of which, is feature discrimination. To address it, one group tries to exploit mining-based strategies (\textit{e.
arxiv.org
'인공지능 > Face Recognition' 카테고리의 다른 글
| Arc Face Easy Margin에 대해 (0) | 2021.03.09 |
|---|---|
| [Paper Review] Curricular Face 정리 (0) | 2021.02.23 |
| Face Recognition 트렌드 정리 (0) | 2021.01.29 |
| [Paper Review] L2Softmax, NormFace 총 정리 (5) | 2021.01.27 |
| [Paper Review] Center loss 정리 (4) | 2021.01.27 |